
We present Apdepth, a diffusion model, and associated fine-tuning protocol for monocular depth estimation.
Based on Marigold, its core innovation lies in addressing the deficiency of diffusion models in feature representation capability. Our model followed Marigold, derived from Stable Diffusion and fine-tuned with synthetic data: Hypersim and VKitti, achieved ideal results in object edge refinement.
We first fine-tuned the model, resolving the issue of excessive inference time by replacing multi-step reasoning with single-step reasoning. Then, we introduced pre-trained models to assist diffusion models in deep estimation learning. we only used Depth Anything V2 small as our "Teacher Model" to aid our model to generate more accurate depth maps, and achieve great result. Finally, we introduced a two-stage training strats, combine MSE_Loss and our Latent_Frequence_Loss to enhance the model's ability to capture edge information.















































































































































In the first stage, we learn robust and generalizable representations by aligning U-Net features with high-quality semantic features from DINOv2, emphasizing global context while avoiding overfitting to low-level textures. Building on these semantic priors, the second stage focuses on depth estimation and detail refinement: it first captures global structure and scale through joint optimization, and then enhances fine details and sharp discontinuities via frequency-domain supervision, achieving both structural accuracy and high-fidelity reconstruction.
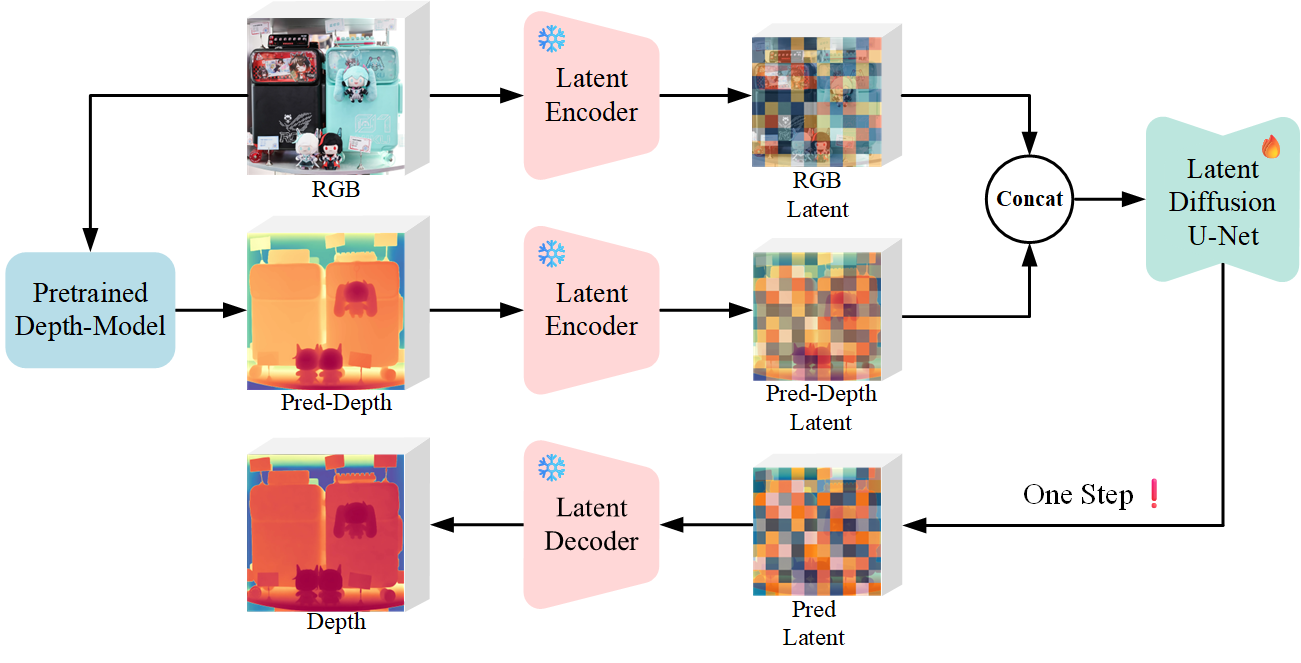
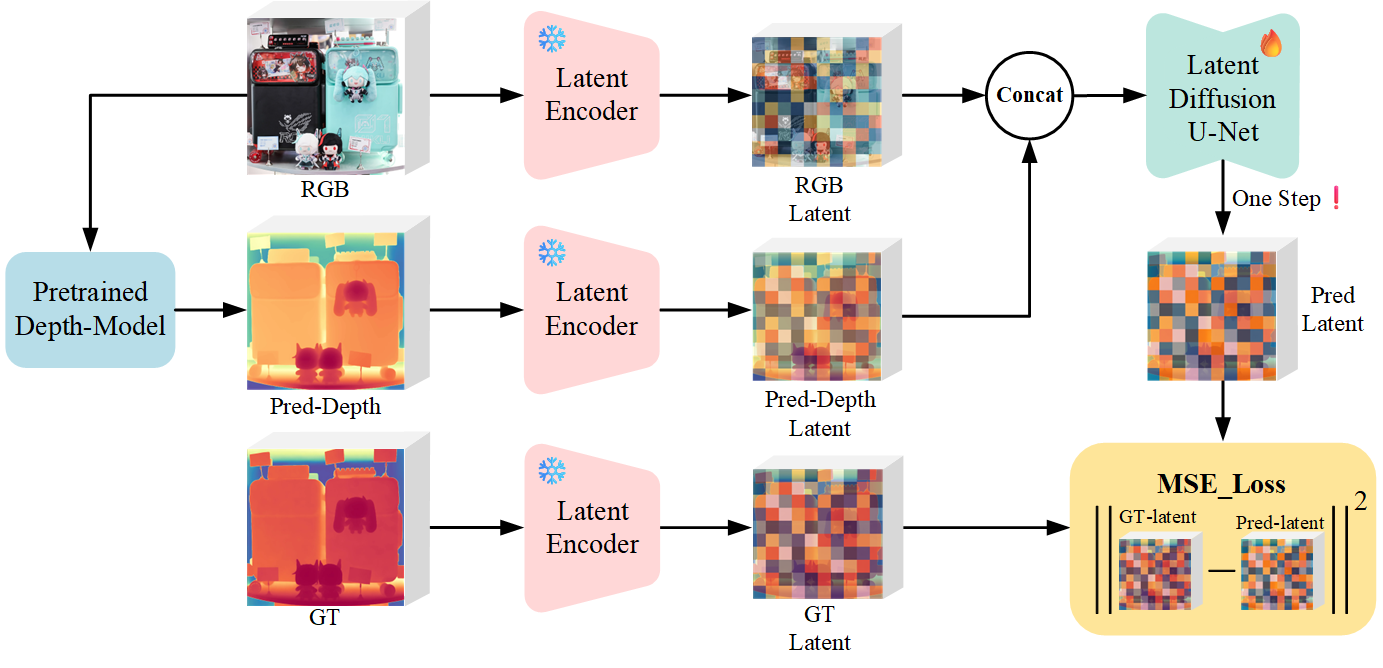
During inference, the input RGB image is first processed by a pretrained depth estimation model to generate a coarse predicted depth map. Both the RGB image and the predicted depth map are encoded into the latent space using the frozen VAE encoder to obtain the corresponding latent representations. These two latents are concatenated and fed into the Latent Diffusion U-Net, which performs only a single denoising step to generate the predicted latent representation. Finally, the latent decoder reconstructs the refined depth map from the predicted latent, producing the final output depth.
We train our model on a single NVIDIA RTX 6000 Ada Generation GPU , 20000 iters * 32 batchs for stage one and 1000 iters * 32 batchs for stage two. It takes around 6 days to complete the whole training process. We test our model on a single NVIDIA Geforce RTX 5090 GPU , result are available below.
